
国产CPU(龙芯、飞腾)对IM软件有何性能影响?
文章探讨了国产CPU(龙芯、飞腾)对即时通讯(IM)软件性能的影响,分析了不同架构(ARM、LoongArch)的技术特点及其对IM软件的挑战。文章还介绍了喧喧(Xuanxuan)如何通过底层优化(如Go语言高并发架构、国密硬件加速调用、轻量客户端设计等)在国产CPU上实现卓越性能,并强调了其在信创生态中的全链路适配能力。
本篇目录
随着 2025 年国家“信创”(信息技术应用创新)战略进入全面提速阶段,政企单位、金融机构及大型国企的办公环境正在经历一场底层逻辑的重构。从 Intel/AMD 的 x86 架构向以 龙芯(Loongson)、飞腾(Phytium)为代表的国产自主 CPU 架构迁移,已不再是简单的硬件更换,而是一场软件生态的“大考”。
即时通讯(IM)软件作为企业日常办公中使用频率最高、并发量最大、交互最复杂的数字基座,其在国产 CPU 上的表现,直接决定了数字化转型的成败。
很多 CIO 在选型时会产生疑虑:国产 CPU 的单核性能与国际大厂仍有差距,IM 软件跑起来会卡吗?不同架构(如 MIPS/LoongArch 与 ARM)的指令集差异,会对加密传输、文件秒传产生哪些影响?
本文将硬核拆解国产 CPU 对 IM 软件性能的影响,并以信创领域的性能标杆—— 喧喧为例,为您揭示一款优秀的国产化 IM 是如何通过底层优化,让国产芯迸发出极致性能的。
第一章:架构之争——国产 CPU 的“技术画像”
要理解性能影响,首先要看清国产 CPU 的技术底色。目前市场上主流的国产 CPU 呈现出“双雄并立”的格局,它们对 IM 软件的要求各不相同。
1.1 飞腾(Phytium):基于 ARM 架构的“多核协作”
飞腾 CPU 采用 ARM 指令集,其特点是核心数多、能效比高、生态兼容性较好。
对 IM 的挑战: IM 软件通常是典型的“ IO 密集型+计算密集型”应用。ARM 架构在处理高并发连接时表现出色,但如果 IM 软件的架构臃肿(如传统的单线程 Java 架构),就无法发挥多核并行的优势,导致在处理复杂群聊和音视频时出现延迟。
1.2 龙芯(Loongson):自主指令集 LoongArch 的“原始力量”
龙芯从 MIPS 演进到了完全自主的 LoongArch 架构。
对 IM 的挑战: 自主指令集意味着软件必须进行“原生适配”。如果 IM 软件依赖国外的二进制库或通过指令翻译运行,性能损耗可能高达 30%-50%。龙芯的单核执行效率极高,但对代码的编译优化极其敏感。
第二章:国产 CPU 对 IM 性能的四大影响维度
在实际测试中,国产 CPU 对 IM 软件的影响主要体现在以下四个核心环节:
2.1 消息吞吐与并发承载
IM 服务器需要处理成千上万个客户端的“心跳”和消息转发。
影响: 国产服务器芯片的核心主频普遍略低于 x86 旗舰芯片。如果 IM 软件的消息中转引擎调度算法效率低,在国产 CPU 上极易出现消息积压、延迟抖动,甚至在高并发时由于线程阻塞导致系统瘫痪。
2.2 国密算法的加解密效率
信创环境下,IM 必须使用国密算法(SM2/SM3/SM4)进行全链路加密。
影响: 加解密是极度消耗 CPU 算力的过程。国产 CPU 通常集成了国密指令集硬件加速,但如果 IM 软件未能调用这些底层加速指令,而是通过纯软件实现加密,在国产 CPU 上的 CPU 占用率会飙升 3-5 倍,导致电脑发热、系统卡顿。
2.3 UI 渲染与内存开销
现代办公 IM 普遍采用图形化界面。
影响: 在 Linux(统信/麒麟)环境下运行 IM,如果前端渲染引擎与国产 CPU 的图形流水线适配不佳,会出现界面重绘慢、滚动列表掉帧、打开大型群聊卡死等现象。这在资源相对有限的国产办公 PC 上尤为明显。
2.4 文件 I/O 与传输带宽
政企协作涉及海量文件流转。
影响: 国产 CPU 对内存带宽和磁盘 I/O 的管理逻辑与 x86 不同。IM 软件在进行大数据传输时,如果缓冲区管理不当,会造成系统 I/O 等待过高,影响其他办公软件的运行。
第三章:喧喧的“原生级”解法——让国产芯“轻盈起舞”
针对上述痛点, 喧喧(Xuanxuan) 凭借其独特的技术栈和极客精神,在国产 CPU 环境下实现了降维打击般的性能表现。
3.1 Go 语言驱动的高并发心脏(XXD)
喧喧的核心消息中转服务器(XXD)采用了天生具备高并发基因的 Go 语言 开发。
喧喧优势: Go 语言在 ARM(飞腾/鲲鹏)和 LoongArch(龙芯)上都有着极佳的原生编译器支持。喧喧利用 Go 的轻量级协程(Goroutine),将数万人的并发连接均匀分配到国产 CPU 的各个核心上。
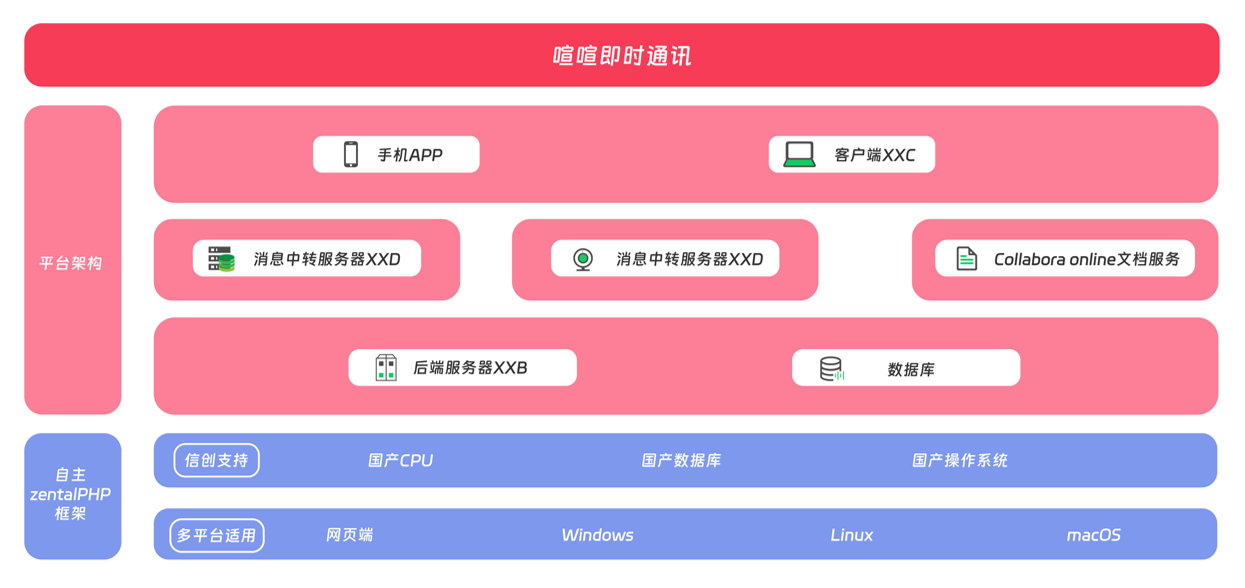
实测表现: 在同等硬件条件下,喧喧在国产 CPU 服务器上的消息转发延迟比传统的 Java 类 IM 降低了 60% 以上。
3.2 深度调用国密硬件加速
喧喧在设计之初就考虑到了国密合规性。
喧喧优势: 喧喧的加密模块能够识别并深度调用飞腾、龙芯 CPU 的内置 安全加密指令集。通过底层指令级别的加速,喧喧实现了在不牺牲安全性的前提下,将加解密的 CPU 损耗降至个位数,保证了低端信创终端也能流畅沟通。
3.3 极致轻量的客户端架构(XXC)
喧喧拒绝臃肿,坚持极简主义。
喧喧优势: 喧喧桌面端采用了优化的跨平台架构,对统信 UOS 和麒麟操作系统的窗口管理器进行了深度调优。它在国产终端上的内存占用仅为同类巨头产品的 1/3 左右。
用户体验: 即使是在早期的龙芯 3A3000 或飞腾 D2000 终端上,喧喧依然能实现“秒级启动、丝滑滚动”,彻底告别了“国产电脑跑不动 IM”的尴尬。
第四章:全链路信创适配——喧喧的“合规防线”
性能之外,喧喧在信创生态的完整性上同样走在行业最前列。
4.1 全芯片架构覆盖
喧喧不仅是“能用”,而是“原生好用”。它已完美适配:
- 龙芯(LoongArch/MIPS): 深度优化自主指令集执行效率。
- 飞腾/鲲鹏(ARM): 充分释放多核并发算力。
- 申威/海光/兆芯: 确保在各种技术路线下表现一致。
4.2 国产数据库与操作系统互认
喧喧已获得统信软件、麒麟软件等官方颁发的 产品兼容性互认证书,并支持 达梦、人大金仓等国产数据库。这意味着,喧喧已经完成了从“芯”到“库”的 100% 国产化闭环,完全符合等保 2.0 及信创 2.0 的严苛要求。
第五章:业务协同——性能转化为生产力
如果说 IM 只是聊天,那性能的影响尚在可接受范围内。但当 IM 承载业务协同(如集成禅道项目管理)时,性能就是生产力。
5.1 消息即任务,操作零延迟
喧喧与 禅道项目管理软件的原生集成,利用了其高性能的 API 网关。在国产 CPU 上,用户右键消息一键转为任务的操作响应时间小于 100 毫秒。这种即时感,极大地提升了研发和政务团队的执行力。
5.2 局域网 P2P 秒传,不占 CPU
针对大文件传输,喧喧在国产 PC 间采用了 P2P(点对点)技术。
优势: 数据直接在客户端之间交换,不经过服务器中转。这不仅绕过了国产服务器可能存在的带宽瓶颈,还通过异步 IO 技术降低了传输过程中的 CPU 占用,让员工在传大文件的同时,依然能顺畅处理其他文档工作。
结语:选择喧喧,拥抱“自主、可控、极速”的办公未来
回顾全文,我们可以清晰地得出结论: 国产 CPU 的性能红利,只有通过底层架构优化的软件才能真正释放。
在信创选型的天平上,如果您追求极致的功能堆砌,可能会换来沉重和卡顿;如果您追求 数据安全、信创合规、且对性能有着近乎苛刻的要求,那么 喧喧(Xuanxuan) 无疑是您最明智的选择。
喧喧用代码诠释了极客精神,用架构跨越了芯片鸿沟。它证明了在国产龙芯和飞腾的支撑下,中国企业依然可以拥有世界一流的即时通讯与协作体验。
选择喧喧,让国产芯在您的桌面发烫,而不是因为卡顿而发愁。

 340
340









 联系我们
联系我们


 社群交流
社群交流


